
Data-Driven Test
The book has now been published and the content of this chapter has likely changed substanstially.Please see page 288 of xUnit Test Patterns for the latest information.
How do we prepare automated tests for our software?
How do we reduce Test Code Duplication?
We store all the information needed for each test in a data file and write an interpreter that reads the file and executes the tests.
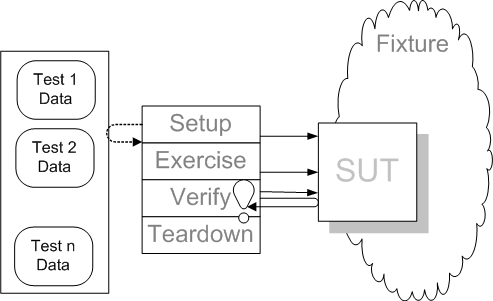
Sketch Data-Driven Test embedded from Data-Driven Test.gif
Testing can be very repetitious not only because we must run the same test over and over again but also because many of the tests are only slightly different. For example, we might want to run essentially the same test with slight different system inputs and verify that the actual output varies accordingly. Each of these tests would consist of the exact same steps. While having this many tests is excellent for ensuring good code coverage, it is not so good for test maintainability. Any change made to the algorithm of one of these tests must be propagated to all the similar tests.
A Data-Driven Test is one way to get excellent coverage while minimizing the amount of test code we need to write and maintain.
How It Works
We write a Data-Driven Test interpreter that contains all the common logic from the tests. We put the data that varies from test to test into the Data-Driven Test file that the interpreter reads to execute the tests. For each test it does the same sequence of actions to implement the Four-Phase Test (page X): First, it retrieves the test data from the file. Second, it sets up the test fixture using the data from the file. Then, it exercise SUT with whatever arguments the file specifies. Third, it compares the actual results produced by the system under test (SUT) (returns values, post test state, etc.) with the expected results from the file. If the results don't match, it marks the test as failed; if the SUT throws an exception, it catches the exception and marks the test accordingly and continues. Fourth, it does any fixture teardown that is necessary. It then moves on to the next test in the file.
A test that would otherwise require a series of complex steps can be reduced to a single line of data in the Data-Driven Test file. Fit is a popular example of a framework for writing Data-Driven Tests.
When To Use It
Data-Driven Test is an alternative strategy to Recorded Test (page X) and Scripted Test (page X) but it can also be used as part of a Scripted Test strategy and Recorded Tests are in fact Data-Driven Tests when played back. Data-Driven Test is an ideal strategy for getting business people involved in writing automated tests. By keeping the format of the data file simple, we can make it possible for the business person to populate the file with data and execute the tests without having to get a technical person to write any test code for them.
We can consider using a Data-Driven Test as part of a Scripted Test strategy whenever we have a lot of different data values with which we wish to exercise the SUT but where the sequence of steps to execute for each data value is pretty much identical. Usually, we discover this similarity over time and refactor first to a Parameterized Test (page X) and then to a Data-Driven Test. We may also have a standard set of steps that we want to arrange in different sequences with different data values much like in an Incremental Tabular Test (see Parameterized Test). This gives us the best coverage with the least test code to maintain and makes it very easy to add additional tests as they are needed.
Another consideration for deciding whether to use Data-Driven Tests is whether the behavior we are testing is data-driven or program-based. If we automate tests for data-driven behavior using Scripted Tests, we'll have to update the test programs whenever the data changes. This is just plain unnatural because this implies that we'll be committing changes to our Repository[SCM] whenever we change the data in our database.(Of course, we should be managing our test data in a version-controlled Repository too, but that is another book; see [RDb] for details.) By making the tests data-driven, changes to the configuration data or meta objects can be driven by changes to the Data-Driven Tests, a much more natural relationship.
Implementation Notes
Our implementation options depend on whether we are using Data-Driven Test as a distinct test strategy or as part of an xUnit-based strategy. Data-Driven Test as a test strategy typically involves using open sources tools such as Fit or less frequently, commercial Recorded Test tools. Data-Driven Test as part of a Scripted Test strategy may involve implementing a Data-Driven Test interpreter within xUnit.
Regardless of which strategy we are using, we should use the appropriate Test Automation Framework (page X) if one is available. By doing so, we have, in effect, converted our tests into two parts: the Data-Driven Test interpreter and the Data-Driven Test files. Both of these assets should be kept under version control so that we can see how they have evolved over time and to allow us to back out misguided changes. It is particularly important to store the Data-Driven Test files in some kind of Repository even though this may be foreign to business users. We can make this transparent if we provide the users with a Data-Driven Test file authoring tool such as Fitnesse or we can set up a "user-friendly" repository such as a document management system that just happens to support version control as well.
It is also important to run these tests as part of the continuous integration process to ensure tests that used to pass are not suddenly failing. This requires some way to keep track of which tests were "green"; one option is to keep two sets of input files and migrate tests that pass from the "still red" file into the "all green" file that is used for regression testing as part of the automatic build process.
Variation: Data-Driven Test Framework (FIT)
We should consider using a pre-built Data-Driven Test framework when we are using Data-Driven Tests as a test strategy. Fit is a framework originally conceived by Ward Cunningham as a way of involving business users in the automation of tests. It is typically used to automate customer tests but it can also be used for unit tests if the number of tests warrant building the necessary fixtures. Fit consists of two parts: The Fit Framework is a generic Data-Driven Test interpreter that reads the input file and finds all the tables in it. It looks in the top left cell of each table for a fixture class name that it then searches our executable for. When it finds a class, it creates an instances and passes control to it as it reads each row and column of the table. We override methods defined by the framework to specify what should happen for each cell in the table. Therefore, a Fit fixture is an adapter that Fit calls to interpret a table of data and invoke methods on the SUT.
The Fit table can also contain expected results from the SUT and Fit takes care of comparing the specified values with the actual values returned by the SUT. Unlike Assertion Methods (page X) in xUnit, Fit does not abandon a test at the first value that does not match the expected value; rather, it colors in each cell in the table with green cells indicating the actual value matched the expected and red cells indicating wrong or unexpected values.
The advantages of using Fit are:
- Much less code to write than building our own test Interpreter[GOF].
- Output that makes sense to a business person, not just a technical person.
- The tests don't stop at the first failed assertion. Fit has a way of communicating multiple failures/errors in a way that allows us to see the failure patterns very easily.
- There is a plethora of different fixture types available to subclass or use as is.
So why wouldn't we use Fit for all our unit testing instead of xUnit? The main disadvantages of using FIT are:
- The test scenarios need to be very well understood before we can build the Fit fixture. We then need to translate the tests logic into a tabular representation; this isn't always a good fit especially for developers who are used to thinking procedurally. While it may be approriate to have testers who can write these fit fixtures for customer tests, it wouldn't be appropriate for true unit tests unless we had close to a 1:1 tester/developer ratio.
- The tests need to employ the same SUT interaction logic in each test. (The tabular data needs to be injected into the SUT during the fixture setup or exercise SUT phases or retrieved from the SUT during the result verification phase.) If we have several different styles of tests that we want to run, we probably have to build one or more different fixtures for each style of test. Building a new fixture is typically more complex than writing a few Test Methods (page X). There is a plethora of different fixture types available to subclass or use as is but this is yet another thing that developers need to learn to do their jobs and even then, not all unit tests are amenable to automation use Fit.
- A further issue is that FIT tests aren't normally integrated into the developers' regression tests run via xUnit. Thus, they would have to be run separately and that introduces the possibility of them not being run at each check in. Some teams include the Fit tests as part of their continuous integration build process to partially mitigate this issue. Other teams have reported great success having a second "customer" build service or server that runs all the customer tests.
Each of these issues is potentially surmountable but all-in-all I would say that xUnit is a more appropriate framework for unit testing than Fit while the reverse is true for customer tests.
Variation: Naive xUnit Test Interpreter
When we have a small number of Data-Driven Tests that we wish to run as part of an xUnit-based Scripted Test strategy, the simplest implementation is to write a Test Method that contains a loop that reads one set of input data values from the file along with the expected results. This is the equivalent of converting a single Parameterized Test and all it's callers into a Tabular Test (see Parameterized Test). As with a Tabular Test, this approach to building the Data-Driven Test interpreter will result in a single Testcase Object (page X) with many assertions. This has several ramifications:
- The entire set of Data-Driven Tests will count as a single test so converting a set of Parameterized Tests into a single Data-Driven Test will result in a reduction in number of tests.
- We will stop executing the Data-Driven Test on the first failure or error. This means we lose a lot of our Defect Localization (see Goals of Test Automation on page X).
- We need to make sure our assertion failures tell us which subtest we were executing when the failure occurred.
We could address the last two issues by including a try/catch inside the loop but around the test logic and continue execution but we need to find a way to report the test results in a meaningful way (e.g. "Failed subtests 1,3 and 6 with ... ".)
We can make it easier to extend the Data-Driven Test interpreter to handle several different kinds of tests in the same data file by including a "verb" or "action word" as part of each entry in the data file. The interpreter then dispatches to a different Parameterized Test based on the action word.
Variation: Test Suite Object Generator
We can avoid the "stop on first failure" problem associated with a Naive xUnit Test Interpreter by having the suite method on the Test Suite Factory (see Test Enumeration on page X) fabricate the same Test Suite Object (page X) structure as the built-in mechanism for Test Discovery (page X). To do this we build a Testcase Object for each entry in the Data-Driven Test file and initialize each object with the test data for the particular test.(This is very similar to how xUnit built-in Test Method Discovery (see Test Discovery) mechanism works except that we are passing in the test data rather than the Test Method name.) That object knows how to execute the Parameterized Test with the data loaded into it when the test suite was built. This ensures that the Data-Driven Test continues executing even after the first Testcase Object encounters an assertion failure. We can then let the Test Runner (page X) handle counting of tests, errors and failures in the normal way.
Variation: Test Suite Object Simulator
An alternative to building the Test Suite Object is to create a Testcase Object that behaves like one. It reads the Data-Driven Test file and iterates over all the tests when asked to run. It must catch any exceptions thrown by the Parameterized Test and continue executing the subsequent tests. When finished, it must report the correct number of tests, failures and errors back to the Test Runner. It also needs to implement any other methods on the standard test interface on which the Test Runner depends such as returning the number of tests in the "suite", returning the names/status of each test in the suite (for the Graphical Test Tree Explorer (see Test Runner), etc.
Motivating Example
Let's assume we have a set of tests as follows:
def test_extref
sourceXml = "<extref id='abc' />"
expectedHtml = "<a href='abc.html'>abc</a>"
generateAndVerifyHtml(sourceXml,expectedHtml,"<extref>")
end
def test_testterm_normal
sourceXml = "<testterm id='abc'/>"
expectedHtml = "<a href='abc.html'>abc</a>"
generateAndVerifyHtml(sourceXml,expectedHtml,"<testterm>")
end
def test_testterm_plural
sourceXml = "<testterms id='abc'/>"
expectedHtml = "<a href='abc.html'>abcs</a>"
generateAndVerifyHtml(sourceXml,expectedHtml,"<plural>")
end
Example ParamterizedTestUsage embedded from Ruby/CrossrefHandlerTest.rb
The succinctness of these tests is made possible by defining the Parameterized Test as follows:
def generateAndVerifyHtml( sourceXml, expectedHtml, message, &block)
mockFile = MockFile.new
sourceXml.delete!("\t")
@handler = setupHandler(sourceXml, mockFile )
block.call unless block == nil
@handler.printBodyContents
actual_html = mockFile.output
assert_equal_html( expectedHtml, actual_html, message + "html output")
actual_html
end
Example ParamterizedTestMethod embedded from Ruby/HandlerTest.rb
The main problem with these tests is that they are still in code when all that is different between them is the data.
Refactoring Notes
The solution, of course, is to extract the common logic of the Parameterized Tests into a Data-Driven Test interpreter and to collect all the sets of parameters in a single data file that can be edited by anyone. We need to write a "main" test that knows what file to read the test data from and a bit of logic to read and parse the test file. This logic can call our existing Parameterized Test logic and let xUnit keep track of the test execution statistics for us.
Example: xUnit Data-Driven Test with XML data file
In this example, we chose to use XML as our file representation. Each test consists of a test element with 3 main parts:
- A action which tells the Data-Driven Test interpreter which test logic to run. (e.g. "crossref"),
- The input to be passed to the SUT. In our case, this is the sourceXml element.
- The HTML we expect the SUT to produce (in the expectedHtml element.
This is all wrapped up in a "testsuite" element:
<testsuite id="CrossRefHandlerTest">
<test id="extref">
<action>crossref</action>
<sourceXml>
<extref id='abc'/>
</sourceXml>
<expectedHtml>
<a href='abc.html'>abc</a>
</expectedHtml>
</test>
<test id="TestTerm">
<action>crossref</action>
<sourceXml>
<testterm id='abc'/>
</sourceXml>
<expectedHtml>
<a href='abc.html'>abc</a>
</expectedHtml>
</test>
<test id="TestTerm Plural">
<action>crossref</action>
<sourceXml>
<testterms id='abc'/>
</sourceXml>
<expectedHtml>
<a href='abc.html'>abcs</a>
</expectedHtml>
</test>
</testsuite>
Example DataDrivenTestXml embedded from Ruby/CrossrefHandlerTest.xml
This XML file could be edited by anyone with an XML editor without any concern for introducing test logic errors. All the logic for verifying the expected outcome is encapsulated by the Data-Driven Test interpreter in much the same way as it would be by a Parameterized Test. For viewing purposes we could hide the XML structure from the user by defining a style sheet and many XML editors will turn the XML into a form-based input to simplify editing.
To avoid dealing with the complexities of manipulating XML, I'll show an example of the interpreter that uses a CSV file as input.
Example: xUnit Data-Driven Test with CSV Input File
The same test as a CSV file would look like this:
ID, Action, SourceXml, ExpectedHtml Extref,crossref,<extref id='abc'/>,<a href='abc.html'>abc</a> TTerm,crossref,<testterm id='abc'/>,<a href='abc.html'>abc</a> TTerms,crossref,<testterms id='abc'/>,<a href='abc.html'>abcs</a> Example DataDrivenTestTxt embedded from Ruby/CrossrefHandlerTest.txt
The interpreter is pretty simple and is built on the logic we already had for our Parameterized Test. This version reads the CSV file and uses Ruby's split function to parse each line.
def test_crossref
executeDataDrivenTest "CrossrefHandlerTest.txt"
end
def executeDataDrivenTest filename
dataFile = File.open(filename)
dataFile.each_line do | line | desc, action, part2 = line.split(",")
sourceXml, expectedHtml, leftOver = part2.split(",") if "crossref"==action.strip generateAndVerifyHtml sourceXml, expectedHtml, desc
else # new "verbs" go before here as elsif's
report_error( "unknown action" + action.strip )
end
end
end
Example DataDrivenTestInterpreter embedded from Ruby/DataDrivenTestInterpreter.rb
Unless we changed the implementation of generateAndVerifyHtml to catch assertion failures and increment a failure counter, this Data-Driven Test will stop executing at the first failed assertion. While it would be fine for regression testing, it would not provide very good Defect Localization.
Example: Data-Driven Test using Fit Framework
If we wanted to have even more control over what the user can do, we could create a Fit "column fixture" with the columns "ID", "Action", "SourceXml" and "ExpectedHtml" and let the user edit an HTML web page instead:

Sketch CrossrefHandlerFitTest embedded from CrossrefHandlerFitTest.gif
When using Fit, the test interpreter is the FIT framework extended by the Fit fixture class specific to the test:
public class CrossrefHandlerFixture extends ColumnFixture {
// input columns:
public String id;
public String action;
public String sourceXML;
// Output columns:
public String expectedHtml() {
return generateHtml(sourceXML);
}
}
Example FitTestFixture embedded from java/com/xunitpatterns/fit/CrossrefHandlerFixture.java
The methods of this fixture class are called by the Fit framework for each cell in each line in the Fit table based on the column headers. Simple names are interpreted as the instance variable of the fixture (e.g. "id" and "source XML") while column names ending in "()" signify a function that Fit calls and compares the result with the contents of the cell.
The resulting output is:
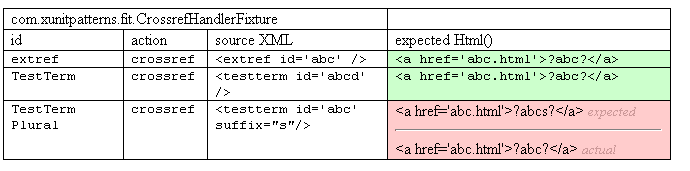
Sketch CrossrefHandlerFitOutput embedded from CrossrefHandlerFitOutput.gif
This colored-in table allows us to get an overview of the results of running one file of tests at a single glance.
Copyright © 2003-2008 Gerard Meszaros all rights reserved