
Database Sandbox
The book has now been published and the content of this chapter has likely changed substanstially.Please see page 650 of xUnit Test Patterns for the latest information.
How do we develop and test software that depends on a database?
We provide a separate test database for each developer or tester.
Sketch Database Sandbox embedded from Database Sandbox.gif
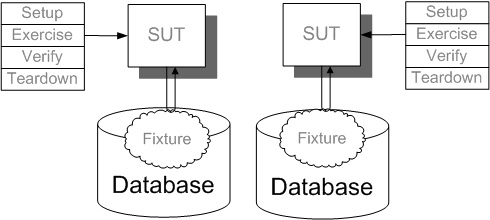
Many applications use a database to store the persistent state of the application. At least some of the tests for such an application will require accessing the database. Unfortunately, a database is a primary cause of Erratic Tests (page X) due to the fact that data may persist between tests. A large part of keeping tests from interacting is ensuring that the test fixtures used by each test do not overlap. This is especially difficult when the development environment contains only a single test database and all tests run by all developers run against the one database.
A Database Sandbox is one way to keep the tests from interacting by accidentally accessing the same records in the database.
How It Works
We provide each user with a separate, self-consistent sandbox in which to work. This sandbox includes their own copy of any code plus most importantly, their own copy of the database. This allows each user to modify the database in any way they see fit and to exercise the application with tests without worrying about any interactions between their tests and the tests of other users.
When To Use It
We should use a Database Sandbox whenever we are building or modifying an application that depends on a database for a significant portion of its functionality. This is especially true if we have chosen to use a Shared Fixture (page X). Using a Database Sandbox will help us avoid Test Run Wars (see Erratic Test) between different users of the database. Depending on how we have chosen to implement the Database Sandbox, it may or may not allow different users to modify the structure of the database. Database Sandbox will not prevent Unrepeatable Tests (see Erratic Test) or Interacting Tests (see Erratic Test) because it is about separating different users (and their test runs) from each other while still allowing tests within a single test run to share a test fixture.
Implementation Notes
The application needs to be made configurable so that the database to be used can be changed without modifying the code. This is typically done by reading the database configuration information from a properties file that is customized in each users' environment.
A Database Sandbox can be implemented many different ways. Fundamentally, the choice comes down to whether we give each user a separate database instance or just simulate one. For the most part, giving each user a real separate database instance is the preferred choice but this can be made impractical by a number of factors, the most prominent of which is the database vendor's licensing regime.
Variation: Dedicated Database Sandbox
We give each developer, tester or test user a separate database instance. This is typically accomplished by installing a lightweight database technology in each user's test environment. Examples of lightweight database technologies include MySql and Personal Oracle. The database instance can be installed on the user's own machine, on a shared test server, or on a dedicated "virtual server" running on a shared server.
a Dedicated Database Sandbox is the preferred solution because it gives the most flexibility. It allows a developer to modify the database schema, load their own test data and so on.
Variation: DB Schema per TestRunner
With DB Schema per TestRunner, we give each developer, tester or test user what appears to be a separate database instance by using built-in database support for multiple schemas.
One considerable advantage over using a Dedicated Database Sandbox is that we can share an Immutable Shared Fixture (see Shared Fixture) defined in a common schema and put each user's mutable fixture in their own private schema. Note that this does not allow them to modify the structure of the database (at least not to the same degree as a Dedicated Database Sandbox.)
Variation: Database Partitioning Scheme
We give each developer, tester or test user a separate set of data within a single Database Sandbox. Each user can modify that data as they see fit but are not allowed to modify the data assigned to other users.
This approach has less database administration overhead but more data administration overhead than the other ways to implement Database Sandbox. It does not allow developers to modify the database schema therefore it is not appropriate for evolutionary database development. It is, however, appropriate for preventing Interacting Tests when applied at the test level. That is, we give each test a unique key such as a CustomerNumber that it uses for all the data. This ensures that other tests within the same test run use different data. Note that this still does not prevent Unrepeatable Tests unless we also use Distinct Generated Values (see Generated Value on page X).
Example: Database Sandbox
I could not come up with a meaningful code sample to illustrate Database Sandbox. Suffice it to say that tests should not have to do anything special to run completely independently from tests being run from other Test Runners (page X).
Copyright © 2003-2008 Gerard Meszaros all rights reserved