
Erratic Test
The book has now been published and the content of this chapter has likely changed substanstially.Please see page 228 of xUnit Test Patterns for the latest information.
One or more tests are behaving erratically; sometimes they pass and sometimes they fail.
Symptoms
We have one or more tests that run but give different results depending on when they are run and who is running them. In some cases, the Erratic Test will consistently give the same results when run by one developer but fail when run by someone else or in a different environment. In other cases, the Erratic Test will give different results when run from the same Test Runner (page X).
Impact
We may be tempted to removed the failing test from the suite to "Keep the Bar Green" but this would result in an (intentional) Lost Test (see Production Bugs on page X). If we choose to keep the Erratic Test in the test suite despite the failures, the known failure may obscure other problems such as another issue detected by the same test(s). Just having a test fail can cause additional failures to be missed because it is much easier to see the change from a green bar to a red bar than to notice that two tests are failing instead of just the one we expected.
Trouble-Shooting Advice
Erratic Tests can be pretty challenging to trouble-shoot because there are so many causes. If the cause cannot be easily determined it may be worthwhile collecting data systematically over a period of time. Where (what environments) did the tests pass and where did they fail? Were all the tests being run or just a subset? Was there any change in behavior when the test suite was run several times in a row? Or if it was run from several Test Runners at the same time?
Once we have some data it should be easier to match up the observed symptoms with those listed for each of the possible causes and narrow down the possibilities to just a few. Then we can collect some more data focusing on differences in symptoms between the possible causes. The following flowchart summarizes the process for determine which cause of Erratic Test we are dealing with:
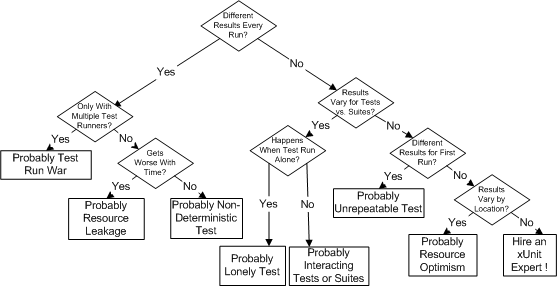
Sketch Erratic Test Trouble-Shooting embedded from Erratic Test Trouble-Shooting.gif
Causes
Tests may be erratic for a number of reasons. The underlying cause can usually be determined through some persistent sleuthing by paying attention to patterns of how and when the tests fail. Some of the causes are common enough to warrant giving them names and specific advice for rectifying them.
Cause: Interacting Tests
Tests depend on each other in some way. Note that Interacting Test Suites and Lonely Test are specific variations of Interacting Tests.
Symptoms
A test that works by itself suddenly fails when:
- another test is added to (or removed from) the suite,
- another test in the suite fails (or starts to pass),
- the test (or another test) is renamed or moved in the source file,
- a new version of the Test Runner is installed.
Root Cause
Interacting Tests are usually caused by tests using a Shared Fixture (page X) with one test depending in some way on the outcome of another test. The cause of Interacting Testss can be described from two perspectives:
- The mechanism of interaction, and
- the reason for interaction.
The mechanism for interaction could be something blatantly obvious such as testing a system under test (SUT) that includes a database or it could be more subtle. Anything the outlives the lifetime of the test can lead to interactions; static variables can be depended on to cause Interacting Tests and should therefore be avoided in both the SUT and the Test Automation Framework (page X)! See the sidebar There's Always an Exception (page X) for an example of the latter causing problems. Singletons[GOF] and Registries[PEAA] are good examples of things to avoid in the SUT if at all possible. If we must use them, it is best to include a mechanism to reinitialize their variables at the beginning of each test.
Tests may interact for a number of reasons either by design or by accident. These reasons include:
- depending on the fixture constructed by the fixture setup phase of another test,
- depending on the changes made to the SUT during the exercise SUT phone of another test, or
- a collision caused by some mutually exclusive action (which may be either of the above) between two tests run in the same test run.
The dependencies may suddenly cease to be satisfied if the depended-on test:
- is removed from the suite,
- is modified to no longer change the state of the SUT,
- fails in its attempt to change the state of the SUT, or
- is run after the test in question (because it was renamed or moved to a different Testcase Class (page X).)
Similarly, collisions may start occurring when the colliding test is:
- added to the suite,
- passes for the first time, or
- runs before the dependent test.
In many of these cases, multiple tests will fail. Some of the test may be failing for a good reason: the SUT is not doing what it is supposed to do. Dependent tests may be failing for the wrong reason: because they were coded to depend on other tests' success. As a result, they may be giving a "false negative" (false failure) indication.
In general, depending on the order of test execution is not a good thing to do because of the problems described above. Most variants of the xUnit framework do not make any guarantees about the order of test execution within a test suite. (TestNG is one example which promotes interdependencies between tests by providing features to manage them.)
Possible Solution
Using a Fresh Fixture (page X) is the preferred solution for Interacting Tests. It is pretty much guaranteed to solve the problem. If we must use a Shared Fixture, we should consider using an Immutable Shared Fixture (see Shared Fixture) to prevent the tests interacting with each other through changes in the fixture by creating from scratch those parts of the fixture that they intend to modify.
If an unsatisfied dependency is caused by another test not having created the expected objects or database data, we should consider using Lazy Setup (page X) to create them in both tests to ensure that the first test to execute creates it for both tests. We can put the fixture set up code into a Creation Method (page X) to avoid Test Code Duplication (page X). If the tests are on different Testcase Classes we can move the fixture set up code to a Test Helper (page X).
If the collision is caused by objects or database data created in our test and not cleaned up, we should consider implementing Automated Fixture Teardown (see Automated Teardown on page X) to remove them safely and efficiently.
A quick way to find out whether we have any tests that do depend on each other is to run the tests in a different order from normal. Running the entire test suite in reverse order would do the trick nicely. Doing this regularly would help avoid accidental introduction of Interacting Testss.
Cause: Interacting Test Suites
A special case of Interacting Tests where the tests are in different test suites.
Symptoms
A test passes when it is run in its own test suite but fails when it is run within a Suite of Suites (see Test Suite Object on page X).
Suite1.run()--> Green Suite2.run()--> Green Suite(Suite1,Suite2).run()--> Test C in Suite2 failsInline code sample
Root Cause
Interacting Test Suites are usually caused by tests in separate test suites trying to create the same resource. When they are run in the same suite, the first one succeeds and the second one fails while trying to create the resource.
The nature of the problem may be obvious just by looking at the test failure or by reading the failed Test Method (page X). If it is not, we can try removing other tests from the (non-failing) test suite one by one. When the failure stops occurring, we simply look at the last test we removed for behaviors that might be causing the interactions with the other (failing) test. In particular, we need to look at anything that might involve a Shared Fixture including all places that class variables are initialized. These may be within the Test Method itself, within a setUp method or in any Test Utility Methods (page X) that are called.
Warning: There may be more than one pair of tests interacting in a test suite! The interaction may also be caused by the SuiteFixture Setup (page X) or Setup Decorator (page X) of several Testcase Classes clashing rather than a conflict between the actual Test Methods!
Variants of xUnit that use Testcase Class Discovery (see Test Discovery on page X) (such as NUnit) may appear to not use test suites but in fact they do; they just don't expect the test automaters to use a Test Suite Factory (see Test Enumeration on page X) to identify the Test Suite Object to the Test Runner.
Possible Solution
We could, of course, eliminate this problem entirely by using a Fresh Fixture but if this isn't within our scope, we could try using an Immutable Shared Fixture to prevent the tests interacting.
If the problem is caused by leftover objects or database rows created by one test which are conflicting with the fixture being created by a later test, we should consider using Automated Teardown to eliminate the need to write error-prone cleanup code.
Cause: Lonely Test
Lonely Test is a special case of Interacting Tests in which a test can be run as part of a suite but cannot be run by itself because it depends on something in a Shared Fixture that was created by another test (e.g. Chained Tests (page X)) or by suite-level fixture setup logic (such as a Setup Decorator.)
We can address it by converting the test to use a Fresh Fixture or by adding Lazy Setup logic to the Lonely Test to allow it to run by itself.
Cause: Resource Leakage
Tests or the SUT are consuming finite resources
Symptoms
Tests run slower and slower or start to fail suddenly. Reinitializing the Test Runner, SUT or Database Sandbox (page X) clears up the problem only to have it start to reappear over time.
Root Cause
Tests or the SUT are consuming finite resources by allocating them and failing to free them. This may make the tests run slower. Over time, all the resources get used up and tests that depend on them start to fail.
This can be caused by one of two types of bugs:
- The SUT can be failing to clean up the resources properly. The sooner we detect this, the sooner we can track it down and fix it.
- The tests could be the ones that are causing the resource leakage by allocating resources as part of fixture setup and failing to clean them up during fixture tear down.
Possible Solution
If it turns out that the problem is in the SUT then the tests have done their job and we can fix the bug. If, however, the tests are what is causing the Resource Leakage then we must eliminate the source of the leaks. If the leaks are caused by failure to clean up properly when tests fail, we may need to ensure that all tests do Guaranteed Inline Teardown (see Inline Teardown on page X) or convert them to use Automated Teardown.
In general, it is a good idea to set the size of all resource pools to 1. This will cause the tests to fail much sooner allowing us to more quickly determine which tests are causing the leak(s).
Cause: Resource Optimism
A test that depends on external resources has non-deterministic results depending on when/where it is run.
Symptoms
A test passes when it is run in one environment and fails when it is run in another environment.
Root Cause
A resource that is available in one environment is not available in another environment.
Possible Solution
If possible, convert the test to use a Fresh Fixture by creating the resource as part of the test's fixture setup phase. This ensures that the resource exists wherever it is run. This may necessitate the use of relative addressing of files to ensure that the specific location in the file system exists regardless or where the SUT is executed.
If an external resource must be used, the resources should be check in to the source code Repository[SCM] so that all Test Runners run in the same environment.
Cause: Unrepeatable Test
A test behaves differently the first time it is run than how it behaves on subsequent test runs.
Symptoms
Either a test passes the first time it is run and fails on all subsequent runs, or it fails the first time and passes on all subsequent runs. Here's an example of what "Pass-Fail-Fail" might look like:
Suite.run()--> Green Suite.run()--> Test C fails Suite.run()--> Test C fails User resets something Suite.run()--> Green Suite.run()--> Test C failsInline code sample
Here's an example of what "Fail-Pass-Pass" might look like:
Suite.run()--> Test C fails Suite.run()--> Green Suite.run()--> Green User resets something Suite.run()--> Test C fails Suite.run()--> GreenInline code sample
Be forewarned that if there are several Unrepeatable Tests in our test suite, we may see something that looks more like:
Suite.run()--> Test C fails Suite.run()--> Test X fails Suite.run()--> Test X fails User resets something Suite.run()--> Test C fails Suite.run()--> Test X failsInline code sample
This is due to test C exhibiting the Fail-Pass-Pass behavior while test X is exhibiting the Pass-Fail-Fail behavior at the same time. It is easy to miss because we'll have a red bar in each case and we'll only notice the difference if we look closely to see which test(s) are failing each time we run the tests.
Root Cause
The most common cause of Unrepeatable Test is the use, either deliberate or accidental, of a Shared Fixture. A test may be modifying the test fixture such that, during a subsequent run of the test suite, the fixture is in a different state. It is most common with a Prebuilt Fixture (see Shared Fixture) but the only true prerequisite is that the fixture outlasts the test run.
The use of a Database Sandbox may isolate our tests from other developers' tests but it won't prevent the tests we run from colliding with themselves or other tests we run.
The use of Lazy Setup to initialize a fixture holding class variable can result in the test fixture not being reinitialized on subsequent runs of the same test suite. In effect, we are sharing the test fixture between all runs started from the same test runner.
Possible Solution
Since a persistent Shared Fixture is a prerequisite for Unrepeatable Test occurring, we can eliminate the problem by using a Fresh Fixture for each test. To fully isolate the tests, we'd have to make sure we have no shared resource such as a Database Sandbox that outlasts the lifetime of individual tests. One option is to replace a database with a Fake Database (see Fake Object on page X). If we must use a persistent data store we should use Distinct Generated Value (see Generated Value on page X) for all database keys to ensure that we are creating different objects for each test and test run. The other alternative is to implement Automated Teardown to remove all newly created objects/rows safely and efficiently.
Cause: Test Run War
Test failures occur at random when several people are running tests simultaneously.
Symptoms
We are running tests that depend on some shared external resource such as a database. From the perspective of a single person running tests, we might see something like:
Suite.run() --> Test 3 fails Suite.run() --> Test 2 fails Suite.run() --> All tests pass Suite.run() --> Test 1 failsInline code sample
Upon describing our problem to our teammates, we discover that they are having the same problem at the same time. When only one of us runs tests, all the tests pass.
Impact
Test Run War can be very, very frustrating because the probability of it occurring increases the closer we get to a code cutoff deadline. This isn't just Murphy's Law kicking in; it really does happen more often! That's because we tend to be committing smaller changes and more frequently as the deadline approaches (think "last minute bug fixing"!). This in turn increases the likelihood that someone else is running the test suite at the same time and that increases the likelihood of test collisions between test runs occurring at the same time.
Root Cause
Test Run War can only happen when we have a globally Shared Fixture that various tests access and sometimes modify. The shared fixture could be a file that must be opened or read by either a test or the SUT or it could be the records in a test database.
Database contention can be caused by:
- Trying to update or delete a record while another test is also updating it.
- Trying to update or delete a record while another test has a read lock (pessimistic locking) on it.
File contention can be caused by trying to access a file that is already opened by another instance of the test running from a different Test Runner.
Possible Solution
Using a Fresh Fixture is the preferred solution for Test Run War. The simpler solution is to give each test runner their own Database Sandbox. This should not involve making any changes to the tests but it will completely eliminate the possibility of a Test Run War. It will not, however, eliminate other sources of Erratic Test because the tests can still interact with each other through the Shared Fixture (the Database Sandbox.) Another option is to switch to an Immutable Shared Fixture by having each test create new objects whenever it plans to change them. his does require changes to the Test Methods.
If the problem is caused by leftover objects or database rows created by one test which are polluting the fixture of a later test, another solution is use Automated Teardown to cleanup after each test safely and efficiently. This, by itself, is unlikely to completely eliminate Test Run War but it might reduce the frequency of it occurring.
Cause: Nondeterministic Test
Test failures occur at random even when only a single Test Runner is running tests.
Symptoms
We are running tests and the results vary each time we run them
Suite.run() --> Test 3 fails Suite.run() --> Test 3 crashes Suite.run() --> All tests pass Suite.run() --> Test 3 failsInline code sample
After comparing notes with our teammates, we rule out Test Run War either because we are the only one running tests or because the test fixture is not shared between users or computers.
As with Unrepeatable Test, having multiple Nondeterministic Test in the same test suite can make seeing the failure/error pattern more difficult because it looks like different tests are failing rather than different results for a single test.
Impact
Debugging Nondeterministic Tests can be very time-consuming and frustrating because the code executes differently each time. Reproducing the failure can be hard and characterizing exactly what causes the failure can take many attempts. (Once it has been characterized, it is often straightforward to replace the random value with a value known to cause the problem.)
Root Cause
Nondeterministic Tests are caused by using different values each time a test is run. Now, there are times when it is good to use different values each time the same test is run. A legitimate use of Distinct Generated Values is when they are used as unique keys for objects stored in a database. Use of generated values as input to an algorithm where the behavior of the SUT is expected to be different for different values can cause Nondeterministic Tests. Examples include:
- Integer values where negative (or even zero) values are treated differently by the system, or where there is a maximum allowable value. If we generate a value at random, the test could fail in some test runs and pass on others.
- String values where the length of string has minimum and/or maximum allowed values. This most commonly occurs accidently when we generate a random or unique numeric value and then convert it to a string representation without using an explicit format that guarantees the length is constant.
It may seem like a good idea to use random values because this improves our test coverage. Unfortunately, it decreases our understanding of the test coverage and the repeatability of our tests. (See the principle Repeatable Test (see Goals of Test Automation on page X).)
Another possible cause of Nondeterministic Tests is the use of Conditional Test Logic (page X) in our tests. This can result in different code paths being executed on different test runs and that makes our tests non-deterministic. A common "reason" for doing this is the Flexible Test (see Conditional Test Logic). Anything that makes the tests less than completely deterministic is a bad idea!
Possible Solution
The first step is to make our tests repeatable by ensuring the tests execute in a completely linear fashion by removing any Conditional Test Logic. Then we can go about replacing any random values with deterministic values. If this results in poor test coverage, we can then add additional tests for the interesting cases we aren't covering. A good way to determine the best set of input values is to use the boundary values of the equivalence classes. If this results in a lot of Test Code Duplication, we can extract a Parameterized Test (page X) or put the input values and expected results into a file read by a Data-Driven Test (page X).
Copyright © 2003-2008 Gerard Meszaros all rights reserved