
Testing With Databases
The book has now been published and the content of this chapter has likely changed substanstially.About This Chapter
In the previous chapter, Organizing Our Tests, we looked at techniques for organizing all our test code. In this chapter I discuss the things we need to consider when our application includes a database. Applications with databases present some special challenges when writing automated tests. Databases are much slower than the processors used in modern computers so tests that interact with the database tend to run much, much slower than tests that can run entirely in memory. But even ignoring the Slow Tests (page X) issue, databases are a ripe source of many test smells in our automated test suites. Some of these smells are a direct consequence of the persistent nature of the database while others are a consequence of choosing to share the fixture instance between tests; I introduced some of these in the Persistent Fixture Management narrative. In this chapter I expand on them and provide a more focused treatment of testing with databases.
Testing With Databases
My first and overriding piece of advice on this subject is:
When there is any way to test without a database, test without the database!
This seems like pretty strong advice but it is so for a reason. Database introduce all sorts of complications into our application and especially into our tests. Tests that require a database run, on average, two orders of magnitude slower that the same tests run without a database.Why Test With Databases?
Many applications include a database to persist objects or data into longer term storage. The database is a necessary part of the application and verifying that the database is used properly is a necessary part of building these applications. Therefore, the use of a Database Sandbox (page X) to isolate developers and testers from production (and each other) is a fundamental practice on almost every project.
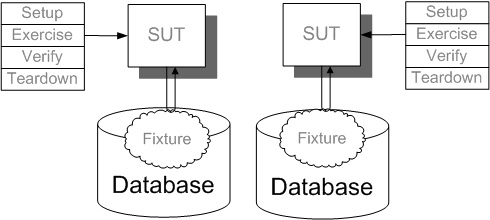
Sketch Database Sandbox embedded from Database Sandbox.gif
Fig. X: A Database Sandbox for each developer.
Sharing a Database Sandbox amongst developers is false economy. Would you make a plumber and an electrician work in the same wall at the same time?
Issues with Databases
A database introduces a number of issues that make test automation harder. Many of these issues are related to the fact that our fixture is persistent. I discussed these back in the Persistent Fixture Management narrative but I will summarize them briefly here.
Persistent Fixtures
Applications with databases present some special challenges when writing automated tests. Databases are much slower than the processors used in modern computers therefore tests that interact with the database tend to run much, much slower than tests that can run entirely in memory. But even ignoring the Slow Tests issue, databases are a ripe source of many test smells in our automated test suites. Common smells include Erratic Tests (page X) and Obscure Tests (page X). Because data in a database has the potential to persist long after we run our test, we must pay special attention to this data to avoid creating tests that can only be run once or tests that interact with each other. These Unrepeatable Tests (see Erratic Test) and Interacting Tests (see Erratic Test) are a direct consequence of the persistence of the test fixture and can result in more expensive maintenance of our tests as the application evolves.
Shared Fixtures
Persistence of the fixture is one thing and choosing to share it is another. Deliberate sharing of the fixture can result in Lonely Tests (see Erratic Test) if some tests depend on other tests to set up the fixture for them. This is called Chained Tests (page X). If we haven't provided each developer with their own Database Sandbox we can end up with a Test Run War (see Erratic Test) between developers. This happens when the tests being run from two or more Test Runners (page X) are interacting with each other by virtue of accessing the same fixture objects in the shared database instance. Each of these behavior smells is a direct consequence of the choosing to share the test fixture. The degree of persistence and scope of fixture sharing have a direct effect on the presence or absence of these smells.
General Fixtures
Another problem with tests that rely on databases is that the database tends to become a large General Fixture (see Obscure Test) that many tests use for different purposes. This is particularly likely when we use a Prebuilt Fixture (page X) to avoid setting up the fixture in each test but it can also be a result of deciding to use a Standard Fixture (page X) when using a Fresh Fixture (page X) strategy. This makes it difficult to determine exactly what each test is specifying. In effect, the database appears as a Mystery Guest (see Obscure Test) in all the tests.
Testing Without Databases
Modern Layered Architecture[DDD,PEAA,WWW] open up the possibility of testing our business logic without using the database at all. We can test the business logic layer in isolation of the other layers of the system using Layer Tests (page X) by replacing the data access layer with a Test Double (page X)
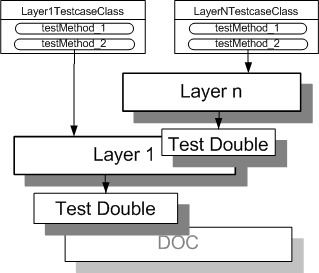
Sketch Layer Tests embedded from Layer Tests.gif
Fig. X: A pair of Layer Tests each testing a different layer of the system.
The Layer Tests allow us to build each layer independently of the other layers. This is especially useful when the persistence layer can be replaced by a Test Double that reduces the Context Sensitivity (see Fragile Test on page X) of the tests.
If our architecture is not sufficiently layered to allow Layer Tests, we may still be able to test without a real database by using a Fake Database (see Fake Object on page X), or an In-Memory Database (see Fake Object). An In-Memory Database is still a database but it stores its tables in memory; this makes it run much faster than a disk-based database. A Fake Database isn't really a database at all; it merely pretends to be a database. As a rule, it is easier to ensure independence of tests using a Fake Database because we typically create a new one as part of our fixture setup logic thereby implementing a Transient Fresh Fixture (see Fresh Fixture) strategy. Both of these strategies allow our tests to run at in-memory speeds thus avoiding Slow Tests. We don't introduce too much knowledge of how the system under test (SUT) is structured as long as we continue to write our tests as round trip tests.
Replacing the database with a Test Double works well as long as we are using the database only as a data repository. Things get more interesting if we are using any vendor-specific functionality such as sequence number generation or stored procedures. This makes replacing the database a bit more challenging because it requires more design for testability. The general strategy is to encapsulate all database interaction with the data access layer. Where the data access layer provides data access functionality, we can simply delegate to the "database object". We must provide test-specific implementations for any parts of the data access layer interface that implement the vendor-specific functionality. A Test Stub (page X) fits the bill nicely here.
If we are taking advantage of vendor-specific database features such as sequence number generation, we will need to provide this functionality when executing the tests in memory. Typically, there won't be any object to substitute with a Test Double because the functionality happens behind the scenes within the database. We can add this functionality into the in-memory version of the application using a Strategy[GOF] object which by default is initialized to a Null Object[PLOPD3]. When run in production, the Null Object does nothing; when run in memory, the Strategy object provides the missing functionality. As an added side benefit, it will be easier to change to a different database vendor once this has been done because the hooks to provide this functionality already exist.(Just one more example of how design for testability improves the design of our applications.)
Replacing the database (or the data access layer) from an automated test implies that we have a way to tell the SUT to use the replacement object. The common ways to do this are through direct Dependency Injection (page X) or by ensuring the business logic layer uses Dependency Lookup (page X) to find the data access layer.
Testing the Database
Assuming we have found ways to test most of our software without using a database, then what? Does the need to test the database disappear? Of course not! We should ensure that the database functions correctly just like any other software we write. We can, however, focus our testing of the database logic so as to reduce the number and kinds of tests we need to write. Recall that tests that involve the database will much, much more slowly than our in-memory tests so we want to keep the number of tests that require the database to a bar minimum.
What kinds of database tests will we require? This depends on how our application uses the database. If we have stored procedures, we should write unit tests to verify their logic. If we have an data access layer that hides the database from the business logic, we should write tests for it.
Testing Stored Procedures
If our application uses stored procedures, we will want to test those as well. We can write tests for stored procedures in one of two ways. A Remoted Stored Procedure Test (see Stored Procedure Test on page X) is written in the same programming language and framework as we write all our other unit tests. It accesses the stored procedure via the same invocation mechanism as used within application logic (either some sort of Remote Proxy[GOF][GOF], Facade[GOF][GOF] or Command[GOF] object [GOF].) The alternative is to write In-Database Stored Procedure Tests (see Stored Procedure Test) in the same language as the stored procedure itself. These tests will run inside the database. There are xUnit family members for several of the most common stored procedure languages; utPLSQL is just one example.
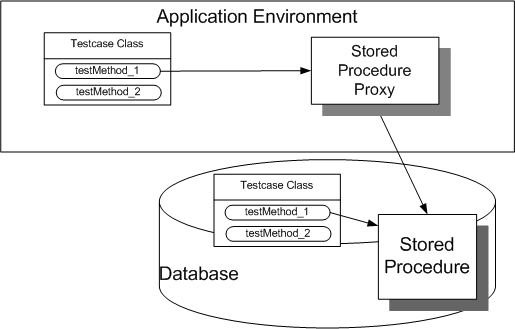
Sketch Stored Procedure Test embedded from Stored Procedure Test.gif
Fig. X: Testing a stored procedure using Self-Checking Tests (see Goals of Test Automation on page X).
There is great value in having automated regression test for stored procedures but care needs to be taken to make them repeatable and robust.
Testing the Data Access Layer
We also want to write some unit tests for the data access layer. For the most part these data access layer tests can be round trip tests but it is useful to have a few layer-crossing tests to ensure that we are putting information into the correct columns. This can be done using xUnit framework extensions for database testing (such as DbUnit for JUnit) to insert data directly into the database (for "Read tests") or to verify the post-test contents of the database (for "Create/Update/Delete" tests.)
Useful trick for keeping our fixture from becoming persistent during data access layer testing is the use of Transaction Rollback Teardown (page X). This is enabled by using the Humble Transaction Controller (see Humble Object on page X) DFT pattern when constructing our data access layer.
Another way to tear down any changes made to the database during the fixture set up or exercise SUT phases of the test is Table Truncation Teardown (page X). This is a somewhat brute force way of deleting data and it only works when each developer has their own Database Sandbox and we want to clear out all the data in one or more tables.
Ensuring Developer Independence
Testing the database means we need to have the real database available for running these tests. I am stating the obvious because every developer needs to have their own Database Sandbox for running these tests. Trying to share a single sandbox amongst several/all developers is a false economy; they will simply end up tripping over each other and wasting a lot of time. (Can you image asking a team of carpenters to share a single hammer?) I have heard a lot of different excuses for not giving each developer their own sandbox, but frankly, none of them really holds water. The most legitimate of the bunch is the cost of a database license for each developer; even this can be surmounted by one of the "virtual sandbox" variations. If the database technology supports it, we can use a DB Schema per TestRunner (see Database Sandbox); otherwise we have to use a Database Partitioning Scheme (see Database Sandbox).
Testing With Databases (Again!)
Suppose we have done a good job layering our system and made it possible to run most of our tests without using the real database. What kinds of tests should we run against the real database? The answer is "as few as possible, but no fewer"! In practice, we want to run at least a representative sample of our customer tests against the database to ensure that the SUT behaves the same way with a database as without. These tests need not access the business logic via the user interface unless there is particular UI functionality that depends on the database; Subcutaneous Tests (see Layer Test) should be adequate in most circumstances.
There are a few patterns that apply only when we are using databases. These include patterns specifically to test the logic in the database itself plus one technique for cleaning up after a test that takes advantage of a feature of the database. In Transaction Rollback Teardown we roll back a database transaction to undo any changes made by the test's fixture setup and exercise phases.
What's Next?
In this chapter we looked at special techniques for testing with databases. I have only scratched the surface of the interactions between agile software development and databases. (For a more complete treatment of the topic refer to [RDb].) In the final narrative chapter A Roadmap to Effective Test Automation I summarize the material we have covered thus far along with some thoughts on how a project team should come up to speed on developer test automation.
Copyright © 2003-2008 Gerard Meszaros all rights reserved