
Introduction
The book has now been published and the content of this chapter has likely changed substanstially.It has been said before but it bears repeating: writing defect-free software is exceedingly difficult. Proof of correctness of real systems is still well beyond our abilities and specification of behavior is equally challenging. Predicting future needs is a hit or miss affair (we'd all be getting rich on the stock market instead of building software systems if we were any good at it!)
Automated verification of software behavior is one of the biggest advances in development methods in the last couple of decades. It is a very developer-friendly practice that has huge benefits in productivity, quality and keeping software from becoming brittle. The very fact that so many developers are now doing it of their own free will speaks for its effectiveness.
This chapter introduces the concept of test automation using various tools including xUnit, why you would do it, etc. and what makes it hard to do well.
Feedback
Feedback is a very important element in many activities. Feedback is what tells us whether our actions are having the right effect. The sooner we get the feedback, the quicker we can react. A good example of this feedback is the rumble strips now being ground into many highways between the main driving surface and the shoulders. Yes, driving off the shoulder gives us feedback that we have left the road. But getting feedback earlier (when our wheels first enter the shoulder) gives us more time to correct and reduces the likelihood of driving off the road at all.
Testing is all about getting feedback on our software. Feedback is one of the essential elements of "agile" or "lean" software development. Having feedback loops in our development process is what gives us confidence in the software that we write. It lets us work more quickly and with less paranoia. It lets us focus on the new functionality we are adding by having the tests tell us whenever we break old functionality.
Testing
The traditional definition of "testing" comes from the world of quality assurance. We test software because we are sure it has bugs in it! So we test and we test and we test some more until we cannot prove there are still bugs in it. But traditionally, this testing occurs after the software is complete. It is a way of measuring quality, not a way of building quality into the product. In many organizations, testing is done by someone other than the software developers. The feedback provided by this kind of testing is very valuable but it comes so late in the development cycle that the value is greatly diminished. It also has the nasty effect of extending the schedule as the problems found are sent back to development for rework followed by another round of testing. So what kind of testing should software developers do to get feedback earlier?
Developer Testing
Rare is the software developer who believes they can write code that "works first time, every time". In fact, most of us are pleasantly surprised when something does work the first time. (I hope I am not shattering any illusions for the non-developer readers out there!)
So developers do testing, too. We want to prove to ourselves that the software works as we intended to. Some developers might do their testing the same way as testers do it: test the whole system as a single entity. Most developers prefer to test their software unit by unit. The "units" may be larger-grained components or they may be individual classes, methods or functions. The key thing that distinguishes these tests from the ones that the testers write is that the units being tested are a consequence of the design of the software, rather than being a direct translation of the requirements(A small percentage of the unit tests may correspond directly to the business logic described in the requirements and the customer tests but a large majority will test the code that surrounds the business logic.).
Automated Testing
Automated testing has been around for several decades. When I worked on telephone switching systems at Nortel's R&D subsidiary Bell-Northern Research in the early 1980's, we already did automated regression and load testing of the software/hardware that we were building. This was done primarily in the context of the "System Test" organization using specialized hardware and software that were programmed with test scripts. The test machines connected to the switch being tested as though it were a bunch of telephones and other telephone switches; it made telephone calls and exercised the myriad of telephone features. This automated testing infrastructure was not suitable for unit testing nor was it generally available to the developers because of the huge amounts of hardware involved.
In the last decade or so, more general-purpose test automation tools have become available for testing applications through their user interfaces. Some of these tools used scripting languages to define the tests but the sexier tools used the "robot user" or "record and playback" metaphor for test automation. Unfortunately, many of the early experiences with these latter tools left the testers and test managers less than satisfied. The cause was high test maintenance costs caused by the "fragile test" problem.
The 'Fragile Test' Problem
Test automation using commercial "record and playback" or "robot user" tools has a bad reputation amongst early users of these tools. Tests automated using this approach often fail for seemingly trivial reasons. It is important to understand the limitations of this approach to testing to avoid falling victim to the common pitfalls. These include Behavior Sensitivity, Interface Sensitivity, Data Sensitivity and Context Sensitivity.
Behavior Sensitivity
If the behavior of the system is changed (e.g. the requirements are changed and the system is modified to meet the new requirements), any tests that exercise the modified functionality will most likely fail when replayed. (A change in behavior could be because the system is doing something different or it could be that it is doing same thing with different timing or sequencing.) This is a basic reality of testing regardless of the test automation approach used. The real problem is that we often need to use that functionality to get the system into the right state to start a test. This leads to a much higher impact of behavioral changes than one might expect.
Interface Sensitivity
Testing the business logic inside the system under test (SUT) via the user interface is a bad idea. Even minor changes to the interface can cause tests to fail even though a human user would say the test should still pass. This is partly what gave test automation tools a bad name in the past decade. The problem occurs regardless of the user interface technology being used but it is worse with some than others. Graphical user interfaces (GUIs) are a particularly hard way to interact with the business logic inside the system. The recent shift to web-based (HTML) user interfaces has made some aspects of test automation easier but has introduced another problem because of the executable code that is needed within the HTML to provide a rich user experience.
Data Sensitivity
All tests assume some starting point, the test fixture; this test context is sometimes called the "pre-conditions" or "before picture" of the test. Most commonly, this test fixture is defined in terms of data that is already in the system. If the data changes, the tests may fail unless great effort has been expended to make the tests insensitive to the data being used.
Context Sensitivity
The behavior of the system may be affected by the state of things outside the system. This could include the states of devices (e.g. printers, servers) other applications, or even the system clock. E.g. the time and/or date of test. Any tests that impacted by this context will be difficult to repeat deterministically without getting control over the context.
Overcoming the Four Sensitivities
The four sensitivities exist regardless of the technology we use to automate the tests but some technologies give us ways to work around the sensitivities while others force us down a particular path. The xUnit family of test automation frameworks gives us a large degree of control; we just have to learn how to use it effectively.
Uses of Automated Tests
Thus far, most of the discussion has centered on regression testing of applications. This is a very valuable form of feedback when modifying existing applications because it helps us catch defects that we have introduced.
Tests as Specification
A completely different use of automated testing is seen in "test-driven development" (TDD) which is one of the core practices of agile methods such as eXtreme Programming. This use of automated testing is more about specification of the behavior of the software yet to be written than it is about regression testing. The effectiveness of TDD comes from the way it lets us separate our thinking about software into two separate phases: What it should do, and how it should do it.
Now hold on a minute! Do not the proponents of Agile software development eschew waterfall-style development? Yes indeed. Agilists prefer to design and build a system feature by feature with working software being available to prove that each feature works before moving on to the next feature. That does not mean we do not do design; it means we do "continuous design"! Taking this to the extreme results in "emergent design" where very little design is done up front but it does not have to be that way. We can combine high-level design (or architecture) up front with detailed design on a feature by feature basis. Either way, it is useful to be able to delay thinking about how to achieve the behavior of a specific class or method for a few minutes while we capture what that behavior should be in the form of an executable specification. After all, most of us have trouble concentrating on one thing at a time let alone several.
Once we have finished writing the tests and verifying that they fail as expected, we switch to making them pass. The tests are now acting as a progress measurement. If we implement the functionality incrementally, we can see each test pass one by one as we write more code. As we work, we keep running all the previously-written tests as regression tests to make sure our changes have not had any unexpected side effects. This is where the true value of automated unit testing lies: in its ability to "pin down" the functionality of the SUT so that the functionality is not changed accidently. That is what allows us to sleep well at night!
Test-Driven Development
A lot of books have been written recently on the topic of test-driven development so I will not be spending a lot of space on that topic. This book is about what the code in the tests looks like rather than when we wrote them. The closest I will get to talking about how the tests come into being is on the topic of refactoring of tests. I will illustrate how to refactor tests written using one pattern into tests that use a pattern with different characteristics.
I am trying to stay "development process agnostic" in this book because I believe that automated testing can help any team regardless of whether they are doing test-driven development, test-first development or test-last development. I also believe that once people learn how to automate tests in a "test last" environment that they will be more inclined to experiment with "test first". Having said that, there are parts of the development process that we still need to talk about because it impacts how easily we can do test automation. There are two key aspects to this. The first is the interplay between Fully Automated Tests (see Goals of Test Automation on page X) and our development integration process and tools. The second is how our development process affects the testability of our designs.
Patterns
In preparing to write this book, I have read a lot of conference papers and books on xUnit-based test automation. Each author seems to have a particular area of interest and favorite techniques. While I do not always agree with their practices, I am always trying to understand why they do it a particular way and when it would be more appropriate to use their techniques than the ones I already use.
This is one of the major differences between examples and prose that merely explain the "how to" of a technique and a pattern. A pattern help the reader understand the why behind the practice so they can make intelligent choices between the alternative patterns and thereby avoid any nasty consequences from surprising them later.
Software patterns have been around for a decade so I hope that most readers are at least aware of the concept. For those that are not, I will provide a more detailed introduction of what makes up a pattern shortly. A pattern is a "solution to a recurring problem". Some problems are bigger than others and too big to solve with a single pattern. That is where the pattern language comes into play; it is a collection (or grammar) of patterns that leads the reader from an overall problem step by step to a detailed solution. In a pattern language, some of the patterns will necessarily be of higher levels of abstraction while others will focus on the details. To be useful, there must be linkages between the patterns so that we can work our way down from the higher level "strategy" patterns to the more detailed "design patterns" and the most detailed "coding idioms".
Patterns vs Principles vs Smells
I have included three different kinds of patterns in this book. The most traditional kind of pattern is the "recurring solution to a common problem". Most of the patterns in this book fall into this general category. I do distinguish between three different levels:
- "Strategy" level patterns are fairly high-level and have far-reaching consequences. The decision to use a Shared Fixture (page X) vs. a Fresh Fixture (page X) takes us down a very different path and leads to a different set of test design patterns. Each of the strategy patterns have their own write-up in the "Strategy Patterns" chapter in the reference section of the book.
- Test "Design" level patterns are used when developing tests for specific functionality. They focus on how we organize our test logic. An example that should be familiar to most readers is the Mock Object (page X) pattern. The test design patterns each have their own write-up and are grouped into chapters in the reference section of the book based on topics like Test Double Patterns.
- Test "Coding Idioms" describe different ways to code a specific test. Many of these are language specific; examples include using block closures for Expected Exception Tests (see Test Method on page X) in Smalltalk and anonymous inner classes for Mock Objects in Java. Some, like Simple Success Test (see Test Method) are fairly generic in that they have analogs in each language. I typically list these idioms as implementation variations or examples within the writeup of a "Test Design Pattern".
At each level there are frequently several alternative patterns that could be used. Of course, I almost always have a preference of which patterns to use but one person's "anti-pattern" may be another person's "best practice pattern". As a result, I have included the patterns that I do not necessarily agree with along with what I believe are the advantages and disadvantages of each. This way the reader can make an informed decision. I have tried to provide linkages to those alternatives in each of the pattern descriptions as well as in the introductory narratives.
The nice thing about patterns is that they provide enough information to make an intelligent decision between several alternatives. The pattern we choose may be affected by the goals we have for test automation. The goals described desired outcomes of our test automation efforts. The goals are supported by a number of principles that codify a belief system about what makes patterns good. The goals are described in the Goals of Test Automation chapter and the principles are described in their own chapter: Principles of Test Automation.
The final kind of pattern is more of an anti-pattern [AP]. These test smells describe recurring problems that our patterns help us address in terms of the symptoms we might observe and the root causes of those symptoms. Code smells were first popularized in Martin Fowler's book [Ref] and applied to xUnit-based testing as test smells in a paper presented at XP2001 [RTC]. The test smells are cross-referenced with the patterns that can be used to banish them as well as the patterns(Some might want to call these patterns "anti-patterns". Just because a pattern often has negative consequences does not imply that it is always bad. Therefore I prefer not to call these anti-patterns; I just do not use them very often.) that are more likely to lead to them. (In a few cases, there is even a pattern and a smell with similar names.) The test smells are introduced in their own chapter: Test Smells.
Pattern Form
A pattern is a "solution to a recurring problem". But what you will be reading in this book are my descriptions of the patterns. The patterns themselves existed before I started cataloging them by virtue of having been invented independently by at least three different test automaters. I took it upon myself to write them down as a way of making the knowledge more easily distributable. But to do that I had to choose a pattern description form.
Pattern descriptions come in many different shapes and sizes. Some have a very rigid structure defined by many headings that help the reader find the various sections. Others read more like literature but may be harder to use as a reference. But all have a common core of information however it is presented.
My Pattern Form
I have really enjoyed reading the works of Martin Fowler and I attribute much of that enjoyment to the pattern form that he uses. Since imitation is the sincerest form of flattery, I have copied his format shamelessly with only a few minor modifications.
The template starts off with the problem statement, the summary statement and a sketch. The italicized problem statement summarizes the core of the problem that the pattern addresses. It is often stated as a question: "How do we ...?" The bolded summary statement captures the essence of the pattern in one or two sentences while the sketch provides a visual representation of the pattern. The untitled section of text immediately after the sketch summarizes why we might want to use the pattern in just a few sentences. It elaborates on the problem statement and includes both the Problem and Context section from the traditional pattern template. One should be able to get a sense of whether we want to read any further by reading this section.
The next three sections provide the meat of the pattern. The "How it Works" section describes the essence of how the pattern is structured and what it is about. It also includes information about the "resulting context" when there are several ways to implement some important aspect of the pattern. This section corresponds to the "Solution" or "Therefore" sections of more traditional pattern forms. The "When to Use It" sections describes the circumstances in which you should consider using the pattern. This section corresponds to the Problem, Forces, Context, and Related Ratterns sections of traditional pattern templates. It also includes information about the Resulting Context where this might affect whether you would want to use this pattern. I also include any "test smells" that would act as an indication that you should use this pattern. The "Implementation Notes" section describes the nuts and bolts of how to implement the pattern. Subheadings within this section indicate key components of the pattern or variations in how the pattern can be implemented.
Most of the concrete patterns include three additional sections. The Motivating Example section provides examples of what the test code might have looked like before this pattern was applied. The section titled Example: {Pattern Name} shows what the test would look like after the pattern was applied. The Refactoring Notes section provides more detailed instructions on how to get from the "Motivating Example" to the "Example: {Pattern Name}".
If the pattern is written up elsewhere I may include a section titled "Further Reading". I do not include a "Known Uses" section unless there is something particularly interesting about them. Most of these patterns have been seen in many, many systems and picking three uses to substantiate them would be arbitrary and meaningless.
Where there are a number of related techniques I have often written them as a single pattern with several variations. If the variations are different ways to implement the same fundamental pattern (namely, solving the same problem the same general way), I list the variations and the differences between them in the "Implementation Notes" section. If the variations are primarily a different reason for using the pattern, I list the variations in the "When to Use It" section.
Historical Patterns and Smells
I struggled a lot with trying to come up a concise enough list of patterns and smells and yet keep historical names whenever possible. I often list the historical name as an alias for the the pattern or smell. In some cases, it made more sense to consider the historical version of the pattern as a specific variation of a larger pattern. In this case I usually include them as a named variation in the "Implementation Notes" section.
Many of the historical smells did not pass the "sniff test". That is, the smell described a root cause rather than a symptom.(The "sniff test" is based on the diaper story in [Ref] wherein Kent Beck asks Grandma Beck "How do I know that it is time to change the diaper?" "If it stinks, change it!" was her response. Smells describe the "stink", not the cause of the stink.). Where an historical test smell describes a cause and not a symptom, I have chosen to move these into the corresponding symptom-based smell as a special kind of variation titled "Cause:". Mystery Guest (see Obscure Test on page X) is a good example.
Referring to Patterns and Smells
I also struggled with a good way to refer to patterns and smells, especially the historical ones. I wanted to be able to use both the historical names when appropriate and the new aggregate names, whichever was more appropriate. I also wanted the reader to be able to see which was which. In the online version, this could be done with hyperlinks but for the printed version I needed a way to represent this as a page number annotation of the reference without cluttering up the entire text with references. The solution I landed on after several tries includes the page number the pattern or smell can be found on first time it is referenced in a chapter, pattern or smell. If the reference is to a pattern variation or the cause of a smell, I include the aggregate pattern or smell name the first time. Note how this second reference to the Mystery Guest cause of Obscure Test shows up without the smell name while references to other causes of Obscure Test such as Irrelevant Information (see Obscure Test) include the aggregate smell name.
Refactoring
Refactoring is a relatively new concept in software development. While people have always had a need to modify existing code, refactoring is a very disciplined approach to changing the design without changing the behavior of the code. It goes hand-in-hand with automated testing because it is very hard to do refactoring without having the safety net of automated tests to prove that you had not broken anything.
Many of the modern integrated development environments (IDE) have built-in support for refactoring. Most of them automate the refactoring steps of at least a few of the refactorings described in Martin Fowler's book [Ref]. What the tools do not tell us is when or why we should use the refactoring. We will have to get a copy of Martin's book for that! Another piece of mandatory reading on this topic is Joshua Kerievsky's book [RtP].
Refactoring tests is a bit different from refactoring production code because we do not have automated tests for our automated tests! If a test fails after a refactoring of the tests, is it because we made a mistake during the refactoring? Just because a test still passes after a test refactoring, can we be sure it will still fail when appropriate? To address this issue many of the test refactorings are very conservative "safe refactorings" that minimize the chance of introducing a change of behavior into the test. We also try to avoid having to do major refactorings of tests by adopting an appropriate test strategy as described in the Test Automation Strategy chapter.
This book focuses more on the target of the refactoring than the mechanics. I do provide a short summary of the refactorings as an appendix but this is not the focus of this book. The patterns themselves are new enough that we have not yet had time to agree on them let alone agree on the best way to refactor to them. A further complication is that there are potentially many starting points for each refactoring target (pattern) and to try to provide detailed refactoring instructions would make this already large book much larger.
Assumptions
In writing this book I assumed that the reader is somewhat familiar with object technology (a.k.a. object oriented programming.) I believe this is a reasonable assumption given that object technology seemed to be a prerequisite before automated unit testing became popular. That does not mean we cannot do it in procedural or functional languages but it may be harder (or at least different).
Different people have different learning styles. Some need to start with the big picture absractions and work down to "just enough" detail. Others can only understand the details and have no need for the "big picture". Some learn best by hearing or reading words. Others need pictures to help them visualize a concept. Yet others learn programming concepts best by reading code. I've tried to accomodate all these learning styles by providing a summary, a detailed description, code samples and a picture wherever possible. Each of these should be Skippable Sections[PLOPD3] for those who don't benefit from that style of learning.
Terminology
This book brings together terminology from two different domains: software development and software testing. That means that some terminology will be unfamiliar to most readers. I will leave it to the reader to refer to the glossary for any terms that they do not understand. I will, however, point out one or two terms here because becoming familiar with these terms is essential to understanding most of the material in this book.
Testing Terminology
Software developers will probably find the term "system under test" (abbreviated throughout this book as SUT) unfamiliar. It is short for "whatever thing we are testing". When we are writing unit tests, the SUT is whatever class or method(s) we are testing; when we are writing customer tests, the SUT is probably the entire application or at least a major subsystem of it.
Any part of the application or system we are building that is not included in the SUT may still be required to run our test because it is called by the SUT or because it sets up prerequisite data that the SUT will use as we exercise it. The former is called a depended-on component (DOC) and both are part of the test fixture.
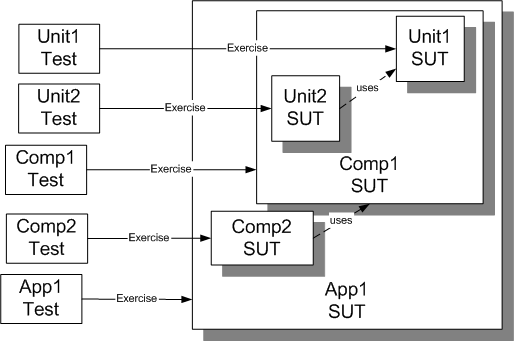
Sketch SUT Example embedded from SUT Example.gif
Fig. X: A range of tests each with its own SUT.
An application, component or unit is only the SUT with respect to a specific set of tests. The "Unit1 SUT" plays the role of DOC (part of the fixture) to "Unit2 Test" and is part of the "Comp1 SUT".
The tests for
Language-Specific xUnit Terminology
Although we have examples in various languages and xUnit family members, JUnit figures prominently in this book. This is simply because this is the language and xUnit framework that most people are at least somewhat familiar with. Many of the translations of JUnit to other languages are pretty faithful ports with only minor changes in class and method names to accomodate the differences in the underlying language. Where this isn't the case I've tried to provide a mapping in the appendix XUnit Terminology Cross-reference. Using Java as the main sample language also means that in some discussions we will refer to the JUnit name of a method and will not list the corresponding method names in each of the xUnit frameworks. For example, a discussion may refer to JUnit'sassertTrue method and not mention that in NUnit it is written as Assert.IsTrue while the SUnit equivalent is should: and the VbUnit equivalent is verify. I leave it to the reader to do the mental swap of method names to the SUnit, VbUnit, Test::Unit, etc. equivalents with which they may be most familiar. I hope that the Intent Revealing Names[SBPP] of the JUnit methods should be clear enough for the purposes of our discussion.
Code Samples
Sample code is always a problem. Samples of code from real projects are typically much too large to include and are usually covered by non-disclosure agreements that preclude their publication. "Toy programs" do not get much respect because "they aren't real". In a book such as this I do not have much choice but to use "toy programs" but I have tried to make them as representative as possible of real projects.
Almost all the code samples came from "real", compilable and executable code so they should not (knock on wood) contain any compile errors unless these were introduced during the editing process. Most of the Ruby examples come from the XML-based publishing system I used to prepare this book while many of the Java and C# samples came from courseware that we use at ClearStream to teach these concepts to ClearStream's clients.
I have tried to use a variety of languages to help illustrate the nearly universal application of the patterns across the members of the xUnit family. In some cases, the specific pattern dictated the use of language because of specific features of either the language or the xUnit family member. In other cases the language was dictated by the availability of third party extensions for a specific member of the xUnit family. Otherwise, the default language for examples is Java with some C# because most people have at least reading level familiarity with them.
Formatting code for a book is a particular challenge due to the recommended line length of just 65 characters. I have had to take some liberties in shortening variable and class names just to reduce the number of lines that wrap. I've also invented some line wrapping conventions to minimize the vertical size of these samples. I hope you do not find them too confusing. You can take solice in the fact that your test code should look a lot "shorter" than mine because you have to wrap much fewer lines!
Diagramming Notation
It has often been said that "A picture is worth a thousand words." Wherever possible, I have tried to include a sketch of each pattern or smell. I've based it loosely on UML (the Unified Modelling Language) but took a few liberties to make it more expressive. For example, I use the aggregation symbol (diamond) and the inheritance symbol (a triangle) of UML class diagrams but I mix classes and objects on the same diagram along with associations and object interactions. Most of the notation is introduced in the patterns in the xUnit Basics chapter in Part 3 so you may find it worthwhile to skim this chapter just to look at the pictures.
I have tried to make this notation "discoverable" simply through comparing sketches but a few conventions are worth pointing out. Objects have shadows while classes and methods do not. Classes have square corners in keeping with UML while methods have round corners. Large exclamation marks are assertions (potential test failures) and a starburst is an error or exception being raised. The fixture is a cloud in keeping with its nebulous nature and any components the SUT depepends on are shown superimposed on the cloud. Whatever the sketch is trying to illustrate is highlighted with heavier lines and darker shading so you should be able to compare two sketches of related concepts to see quickly what is emphasized in each.
Limitations
As you use these patterns, please keep in mind that I could not have seen every possible test automation problem and I certainly have not seen every solution to every problem; there may well be other, possibly better, ways to solve some of these problems. These are just the ones that have worked for me and for the people I have been communicating with. Accept everyone's advice with a grain of salt!
My hope is that these patterns will give you a starting point for writing good, robust automated tests. With luck, you will avoid many of the mistakes we made on our first attempts and will go on to invent even better ways of automating tests. I'd love to hear about them!
Copyright © 2003-2008 Gerard Meszaros all rights reserved